


AWS SageMaker的核心功能
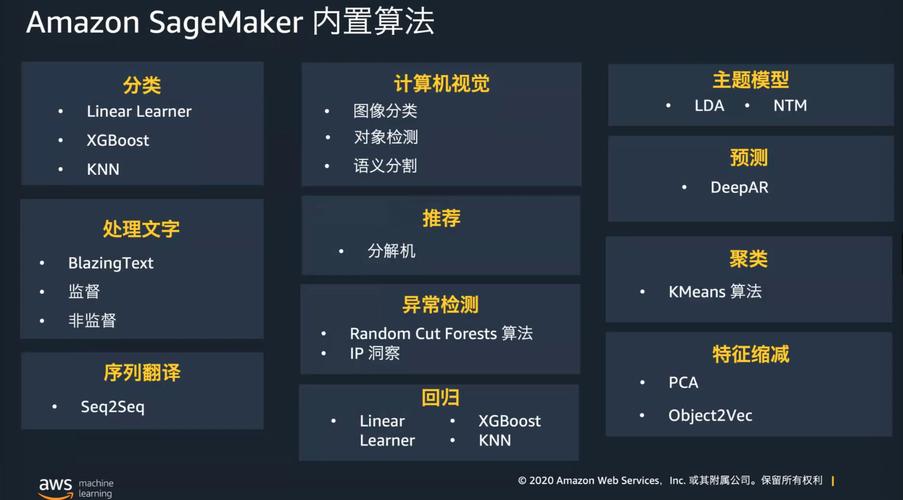
AWS SageMaker提供了从数据准备到模型部署的完整机器学习工作流。它支持多种数据输入方式,包括S3存储、数据库以及实时数据流。SageMaker内置了多种机器学习算法,涵盖了分类、回归、聚类等多种任务。它还支持自定义算法,允许用户根据自己的需求进行扩展。SageMaker提供了自动模型调优功能,能够根据数据特征自动选择最佳的超参数组合。
使用AWS SageMaker的步骤
第一步:数据准备
在使用AWS SageMaker之前,需要准备好数据集。你可以将数据上传到S3存储桶中,或者直接使用SageMaker提供的数据处理工具进行数据清洗和预处理。SageMaker还支持与其他AWS服务(如AWS Glue)集成,方便用户进行数据ETL操作。
第二步:模型训练
在数据准备完成后,你可以选择使用SageMaker内置的算法或自定义算法进行模型训练。SageMaker提供了多种训练实例类型,用户可以根据数据集的大小和复杂性选择合适的实例。训练过程中,SageMaker会自动监控训练进度,并提供详细的日志和指标,方便用户进行调试和优化。
第三步:模型部署
模型训练完成后,你可以使用SageMaker进行模型部署。SageMaker支持多种部署方式,包括实时推理、批量推理以及边缘设备部署。你可以选择将模型部署到SageMaker托管的终端节点上,或者导出模型文件进行本地部署。SageMaker还提供了自动扩展功能,能够根据流量自动调整资源,确保服务的高可用性和稳定性。
AWS SageMaker的最佳实践
为了充分发挥AWS SageMaker的潜力,以下是一些最佳实践建议:尽量使用SageMaker内置的算法和工具,以减少开发时间和成本。合理选择训练实例类型,避免资源浪费。定期监控模型性能,及时进行模型更新和优化。利用SageMaker的自动调优功能,提高模型的准确性和效率。
AWS SageMaker是一个功能强大且易于使用的机器学习平台,能够帮助用户快速构建和部署机器学习模型。通过本教程的学习,你应该已经掌握了AWS SageMaker的核心功能、使用步骤以及最佳实践。希望这些内容能够帮助你在实际项目中更好地应用AWS SageMaker,提升你的机器学习能力。
常见问题解答
1. AWS SageMaker支持哪些编程语言?
AWS SageMaker支持多种编程语言,包括Python、R、Java和Scala。用户可以根据自己的喜好和项目需求选择合适的语言进行开发。
2. 如何选择合适的训练实例类型?
选择训练实例类型时,应考虑数据集的大小、复杂性以及训练时间。对于小型数据集和简单任务,可以选择较低配置的实例;对于大型数据集和复杂任务,建议选择高性能的实例。
3. AWS SageMaker的自动调优功能如何工作?
AWS SageMaker的自动调优功能通过多次训练和评估,自动选择最佳的超参数组合。用户只需指定调优范围和目标指标,SageMaker会自动完成剩余的工作。