


Linux语音识别引擎的基本原理
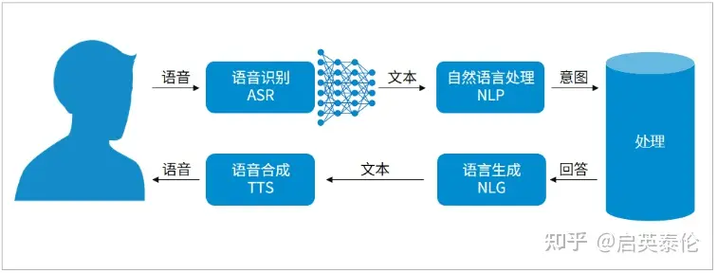
Linux语音识别引擎的核心是基于声学模型和语言模型的识别技术。声学模型负责将语音信号转换为文本,而语言模型则用于提高识别的准确性。在Linux系统中,常见的语音识别引擎包括CMU Sphinx、Kaldi和Google的Speech-to-Text API等。这些引擎通过不同的算法和技术实现语音到文本的转换,适用于各种应用场景。
Linux语音识别引擎的应用场景
智能家居控制
在智能家居领域,Linux语音识别引擎可以用于控制家电、灯光和安防系统。通过语音指令,用户可以轻松实现家居设备的远程控制,提升生活的便利性和舒适度。
语音助手开发
语音助手是Linux语音识别引擎的另一个重要应用场景。开发者可以利用开源的语音识别引擎,构建个性化的语音助手,实现语音搜索、日程管理和信息查询等功能。
如何在Linux系统上配置语音识别引擎
在Linux系统上配置语音识别引擎需要一定的技术基础。用户需要安装相应的语音识别软件包,如CMU Sphinx或Kaldi。通过命令行或图形界面进行配置和测试。本文将详细介绍CMU Sphinx的安装和配置步骤,帮助用户快速上手。
Linux语音识别引擎为开发者和用户提供了强大的语音识别能力,适用于各种应用场景。通过本文的介绍,相信你已经对Linux语音识别引擎有了更深入的了解。希望本文能够帮助你在Linux系统上成功配置和使用语音识别技术,提升你的工作效率和生活质量。
常见问题解答
问题1:Linux语音识别引擎的准确性如何?
Linux语音识别引擎的准确性取决于所使用的引擎和模型。CMU Sphinx和Kaldi等开源引擎在特定场景下可以达到较高的识别率,但与商业引擎相比仍有一定差距。
问题2:如何在Linux系统上提高语音识别的准确性?
提高语音识别准确性的方法包括使用高质量的麦克风、优化声学模型和语言模型,以及在特定场景下进行模型训练和调优。
问题3:Linux语音识别引擎支持哪些语言?
Linux语音识别引擎支持多种语言,包括英语、中文、西班牙语等。用户可以根据需要下载和配置相应的语言模型。