


语音识别的工作原理
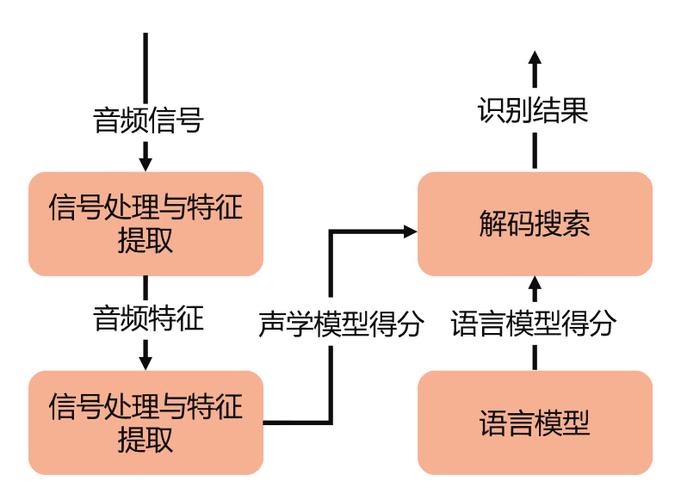
语音识别技术的核心是将人类语音信号转换为计算机可识别的文本信息。其工作流程主要包括以下几个步骤:
语音信号采集
通过麦克风等设备采集人类语音信号,将其转换为数字信号。这一过程需要考虑环境噪音、麦克风质量等因素,以确保语音信号的清晰度。
特征提取
从采集到的语音信号中提取出能够代表语音特征的信息,如梅尔频率倒谱系数(MFCC
)、线性预测编码(LPC)等。这些特征能够有效区分不同的语音单元。
声学模型匹配
将提取到的语音特征与预先训练好的声学模型进行匹配,识别出最可能的语音单元序列。常用的声学模型包括隐马尔可夫模型(HMM
)、深度神经网络(DNN)等。
语言模型解码
结合语言模型对识别出的语音单元序列进行解码,得到最终的文本输出。语言模型能够根据上下文信息提高识别准确率。
语音识别的关键技术
语音识别技术的发展离不开以下几个关键技术的支撑:
深度学习技术
深度学习算法,特别是循环神经网络(RNN)和卷积神经网络(CNN
),在语音识别中得到了广泛应用。这些算法能够自动学习语音特征,显著提高了识别准确率。
大数据技术
语音识别模型的训练需要大量的语音数据。大数据技术为语音数据的采集、存储和处理提供了有力支持,使得模型训练更加高效。
云计算技术
云计算平台为语音识别服务提供了强大的计算能力和存储资源,使得语音识别应用能够快速部署和扩展。
边缘计算技术
边缘计算技术将部分语音识别任务转移到终端设备上执行,减少了数据传输延迟,提高了实时性。
语音识别的应用场景
语音识别技术已经广泛应用于各个领域,主要包括:
语音识别技术的未来发展趋势
随着人工智能技术的不断进步,语音识别技术将朝着以下方向发展:
语音识别技术作为人工智能领域的重要分支,正在深刻改变人机交互方式。随着技术的不断进步,语音识别将在更多领域发挥重要作用,为人类生活带来更多便利。
常见问题解答
Q1: 语音识别技术的准确率如何?
A1: 目前主流语音识别技术在安静环境下的准确率已经达到95%以上,但在噪音环境或面对不同口音时,准确率可能会有所下降。
Q2: 语音识别技术可以识别多种语言吗?
A2: 是的,现代语音识别系统通常支持多种语言的识别,但不同语言的识别准确率可能会有所不同。
Q3: 语音识别技术需要联网使用吗?
A3: 不一定。部分语音识别功能可以在本地设备上完成,但更复杂的识别任务通常需要联网使用云端资源。
Q4: 语音识别技术会侵犯隐私吗?
A4: 正规的语音识别服务提供商会严格遵守隐私保护法规,不会擅自收集或使用用户的语音数据。用户在使用时应注意选择可信赖的服务提供商。