


异常检测的基本概念
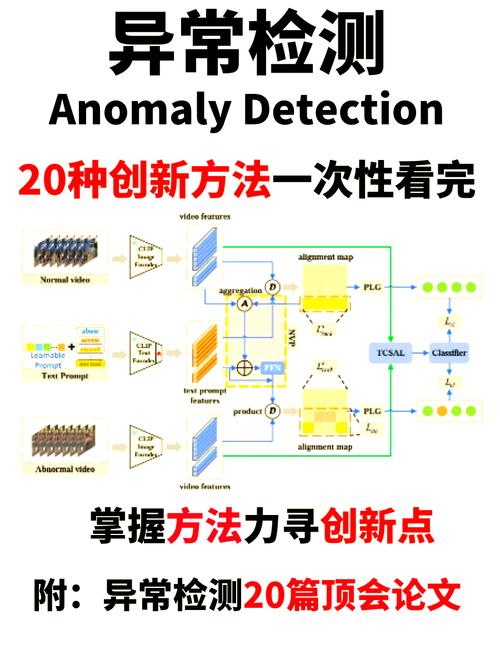
异常检测,又称为离群点检测,是指在数据集中识别出那些与大多数数据显著不同的数据点。这些异常点可能是由于数据录入错误、设备故障、欺诈行为等原因产生的。异常检测的目标是通过分析数据,发现这些异常点,并采取相应的措施。
异常检测的主要方法
统计方法
统计方法是异常检测中最传统的方法之一。它基于数据的统计分布,假设正常数据点符合某种已知的分布(如正态分布),而异常点则偏离这种分布。常见的统计方法包括Z-score、Grubbs' test等。
机器学习方法
随着机器学习技术的发展,越来越多的机器学习方法被应用于异常检测。这些方法包括聚类分析、支持向量机(SVM)、孤立森林(Isolation Forest)等。机器学习方法能够处理高维数据,并且在复杂的数据集中表现出色。
深度学习方法
近年来,深度学习方法在异常检测中也得到了广泛应用。深度学习方法,如自编码器(Autoencoder)、生成对抗网络(GAN)等,能够自动学习数据的特征,并在大规模数据集中进行异常检测。
异常检测的应用场景
异常检测在多个领域都有着重要的应用。以下是几个典型的应用场景:
异常检测的实际案例
在实际应用中,异常检测已经取得了显著的成果。,某银行通过使用孤立森林算法,成功识别出了多起信用卡欺诈案件,减少了大量的经济损失。又如,某互联网公司通过使用自编码器模型,成功检测出了多起网络入侵事件,保障了用户数据的安全。
异常检测是一项重要的技术,它在多个领域都有着广泛的应用。通过掌握异常检测的方法和应用场景,我们能够更好地发现数据中的异常点,并采取相应的措施,保障系统的安全和稳定。
常见问题:
异常检测和分类的主要区别在于数据的分布。分类任务通常假设数据是均匀分布的,而异常检测则假设异常点是稀疏的,与大多数数据显著不同。
异常检测的难点在于异常点的定义和检测方法的选择。异常点的定义往往依赖于具体的应用场景,而检测方法的选择则需要根据数据的特性进行权衡。
评估异常检测的效果通常使用准确率、召回率、F1分数等指标。还可以通过ROC曲线、AUC值等指标进行评估。