


分库分表的基本概念
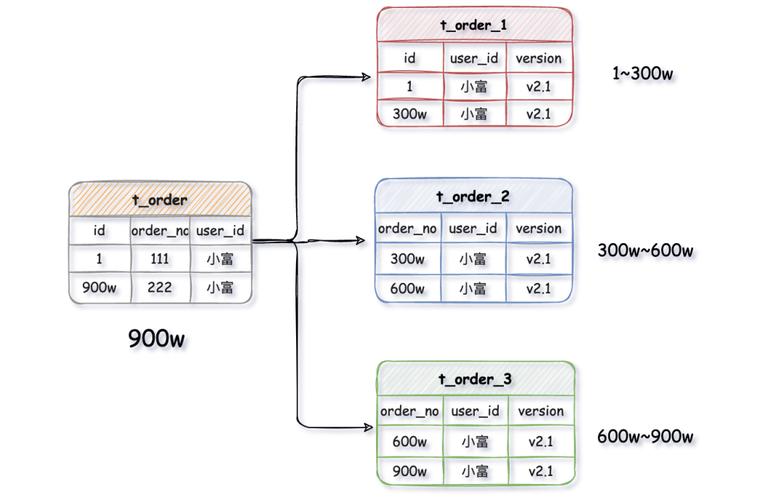
分库分表是指将原本存储于单一数据库中的数据,按照特定规则分散到多个数据库或数据表中的技术方案。这种架构设计主要解决单库单表在数据量增大时面临的性能瓶颈问题。从实现方式上可以分为水平拆分和垂直拆分两种主要类型。
水平拆分与垂直拆分的区别
水平拆分(横向拆分)是指按照数据行进行拆分,将同一个表的不同行数据分散到不同的数据库或表中。将用户表按照用户ID的哈希值分散到4个数据库中。这种方式保持了表结构的完整性,每个分表都包含相同的字段。
分库与分表的选择策略
分库是指将不同的表分散到不同的数据库实例中,而分表则是将同一个表的数据分散到同一个数据库的不同表中。分库能够更好地利用多台服务器的资源,但跨库事务处理复杂;分表实现相对简单,但无法解决单库连接数限制问题。
分库分表的实现技术
现代分库分表方案主要分为客户端分片和中间件分片两种实现方式。客户端分片通过在应用层实现数据路由逻辑,而中间件分片则通过专门的代理层处理数据分发。
主流分库分表中间件对比
分片键的选择原则
分片键的选择直接影响系统性能和扩展性。理想的分布键应具备高离散性、业务相关性和查询相关性。常见的分片键包括用户ID、订单ID、时间戳等。应避免选择可能产生热点数据的字段作为分片键。
分库分表带来的挑战与解决方案
虽然分库分表解决了单库性能问题,但也引入了新的技术挑战,需要开发者特别注意并采取相应解决方案。
分布式事务处理
跨库事务是分库分表架构中的难点问题。常见的解决方案包括:XA协议、TCC柔性事务、SAGA模式、本地消息表等。在实际应用中,应根据业务特点选择合适的事务方案,必要时可以牺牲强一致性换取更高的可用性。
跨库JOIN查询优化
分库后原本简单的SQL JOIN操作变得复杂。应对策略包括:冗余关键字段避免JOIN、使用内存计算合并结果、建立全局索引表等。在数据模型设计阶段就应考虑分库后的查询需求,合理设计冗余字段。
分布式ID生成方案
分库分表环境下需要保证ID全局唯一。常用方案包括:UUID、数据库自增序列、Redis原子操作、雪花算法(Snowflake)等。其中雪花算法因其有序性和高性能成为主流选择。
分库分表的最佳实践
根据众多互联网公司的实践经验,实施分库分表时应遵循一些基本原则和最佳实践,以确保系统稳定性和可维护性。
分库分表的时机判断
不应过早进行分库分表,应先尝试其他优化手段。一般当单表数据量超过500万行,或数据库服务器CPU利用率持续高于70%时,才考虑分库分表。过早拆分会增加系统复杂度,降低开发效率。
平滑迁移方案
数据迁移是分库分表实施的关键环节。推荐采用双写方案逐步迁移:先保持旧库同时写入新旧库,验证无误后再切换读操作,完全切到新库。整个过程应具备回滚能力,确保数据安全。
监控与扩容规划
分库分表后应建立完善的监控体系,关注各分片的数据均衡性和性能指标。设计时应考虑未来扩容需求,选择支持动态扩容的分片策略,避免数据迁移带来的停机时间。
分库分表是应对大数据量、高并发场景的有效解决方案,但同时也带来了系统复杂度的显著提升。开发者需要深入理解业务特点和数据访问模式,选择合适的分片策略和中间件,才能构建出既高性能又易于维护的分布式数据库架构。随着云原生技术的发展,分库分表方案也在不断演进,未来将更加智能化和自动化。
常见问题解答
问题1:什么时候应该考虑分库分表?
当单表数据量超过500万行,或数据库服务器CPU利用率持续高于70%,且通过索引优化、读写分离等手段仍无法满足性能需求时,就应该考虑分库分表。
问题2:分库分表后如何保证ID唯一性?
可以采用分布式ID生成方案,如雪花算法(Snowflake),它通过结合时间戳、工作机器ID和序列号来生成全局唯一且有序的ID,非常适合分库分表场景。
问题3:分库分表后如何进行跨库JOIN查询?
有几种解决方案:1) 避免使用JOIN,通过冗余字段或应用层组装数据;2) 使用内存计算合并多个分片的查询结果;3) 建立全局索引表;4) 考虑使用支持分布式JOIN的中间件如ShardingSphere。
问题4:如何选择合适的分片键?
理想的分片键应具备高离散性(数据均匀分布
)、业务相关性(与查询条件匹配)和稳定性(不频繁变更)。常见选择包括用户ID、订单ID等,应避免选择可能产生热点数据的字段。