


监控告警系统的基本架构
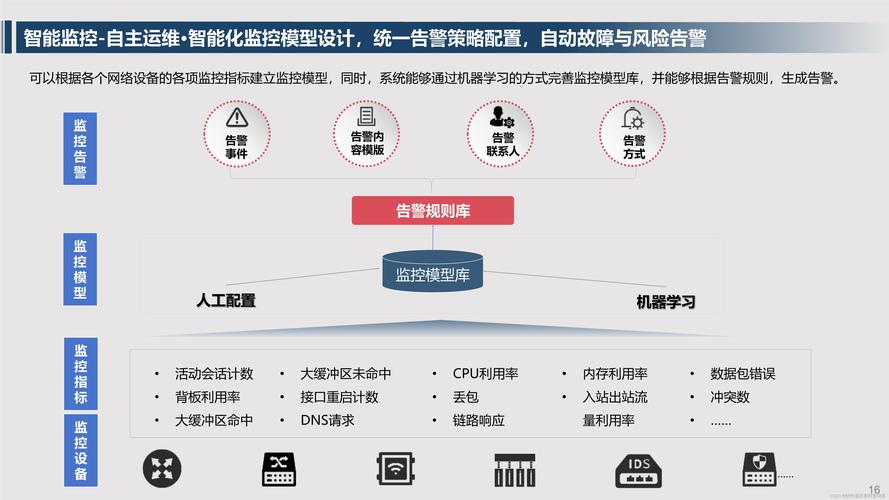
现代监控告警系统通常采用分层架构设计,从数据采集、传输、存储到分析告警形成完整闭环。在数据采集层,Agent代理、SNMP协议、API接口等多种方式实时收集各类指标数据;数据传输层通过消息队列或流处理平台确保海量监控数据的高效传输;数据存储层则采用时序数据库专门优化时间序列数据的写入和查询性能;最上层的分析告警引擎通过预定义的规则和算法,对异常指标进行智能识别和告警触发。
监控告警的关键技术指标
系统性能监控指标
CPU使用率、内存占用、磁盘I/O、网络带宽等基础资源指标是监控告警的首要关注点。通常需要设置多级阈值,如当CPU使用率超过80%时触发警告告警,超过90%时触发严重告警。同时,这些指标的异常波动模式也值得关注,如CPU使用率在短时间内剧烈震荡可能预示着更深层次的问题。
应用服务质量指标
应用响应时间、错误率、吞吐量等指标直接反映业务系统的健康状态。对于关键业务接口,需要设置SLA级别的监控告警,如"API平均响应时间超过500ms"或"HTTP 5xx错误率超过0.1%"。这些指标往往需要从应用日志或APM工具中提取,并与基础设施监控数据关联分析。
告警策略的最佳实践
有效的告警策略需要平衡敏感度和实用性,避免"告警疲劳"现象。推荐采用"分级告警"机制,根据问题严重程度将告警分为紧急、重要、警告等不同等级。同时实施"告警聚合"策略,将相同根源的多个告警合并处理,减少重复告警干扰。"告警静默"功能可以在已知维护窗口期临时屏蔽非关键告警,而"告警依赖"设置可以避免因底层故障导致的级联告警风暴。
监控告警的未来发展趋势
人工智能技术正在深刻改变监控告警领域。基于机器学习的异常检测算法可以自动学习系统正常行为模式,识别传统阈值方法难以发现的潜在问题。预测性告警则通过时序预测模型,在问题实际发生前发出预警。可观测性理念的兴起推动监控告警从单纯的指标监控向日志、追踪、指标三位一体的综合监控体系演进,为复杂分布式系统提供更全面的可见性。
监控告警系统作为IT运维的中枢神经系统,其重要性随着企业数字化转型不断凸显。从基础架构监控到全栈可观测性,从被动响应到主动预防,监控告警技术持续演进,为企业业务稳定运行保驾护航。构建智能、精准、高效的监控告警体系,已成为现代企业提升运维效能、保障业务连续性的战略选择。
常见问题解答
问题1:如何避免监控告警系统的"误报"问题?
答:可以通过设置合理的告警阈值、增加异常持续时间判定条件、采用多指标联合判断等方法来减少误报。机器学习算法也能帮助区分真实异常和正常波动。
问题2:监控告警系统应该覆盖哪些关键业务指标?
答:除基础资源指标外,必须监控核心业务交易量、成功率、关键路径响应时间等直接影响用户体验和收入的指标,这些往往是业务SLA的重要组成部分。
问题3:如何处理监控告警系统的"告警风暴"?
答:建立告警分级制度,实施告警聚合和抑制策略,设置合理的告警依赖关系,并通过自动化工具对告警进行智能分类和路由,可以有效缓解告警风暴问题。