


数据一致性的基本概念
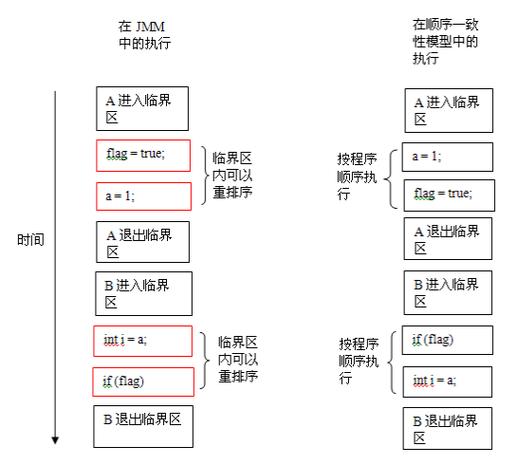
数据一致性是分布式系统设计的核心问题之一,它关系到系统的可靠性和正确性。在理想情况下,无论用户访问系统中的哪个节点,都应该获得相同的数据视图。在网络延迟、节点故障等现实条件下,实现强一致性往往需要付出性能代价。数据一致性模型通常分为强一致性、弱一致性和最终一致性等不同级别,每种模型都有其适用的场景和权衡考虑。
常见的数据一致性实现机制
1. 两阶段提交协议(2PC)
两阶段提交是保证分布式事务原子性的经典协议。在第一阶段,协调者询问所有参与者是否可以提交事务;在第二阶段,根据参与者的反馈决定提交或中止事务。虽然2PC能够提供强一致性保证,但它存在阻塞问题和单点故障风险,不适合高可用性要求的场景。
2. 三阶段提交协议(3PC)
三阶段提交是对2PC的改进,通过引入预提交阶段来减少阻塞时间。3PC在协调者故障时能够更快恢复,提高了系统的可用性。它仍然无法完全解决网络分区情况下的数据一致性问题,且实现复杂度更高。
3. Paxos和Raft共识算法
Paxos和Raft是分布式系统中广泛使用的共识算法,它们能够在节点故障的情况下保证数据一致性。Raft算法相比Paxos更易于理解和实现,已被许多分布式数据库和协调服务采用。这些算法通过选举领导者和日志复制机制来确保所有节点达成一致的状态。
不同场景下的数据一致性策略
在实际系统设计中,选择何种一致性级别需要根据业务需求进行权衡。金融交易系统通常要求强一致性,而社交网络等场景可以接受最终一致性。CAP理论告诉我们,在网络分区情况下,必须在一致性和可用性之间做出选择。现代分布式系统常采用多版本并发控制(MVCC
)、乐观锁等技术来平衡一致性和性能。
数据一致性的监控与验证
确保数据一致性不仅需要在设计阶段选择合适的机制,还需要在运行时进行持续监控。一致性哈希可以帮助均匀分布数据,减少迁移开销。定期的一致性检查可以通过校验和、数据对比等方式发现潜在问题。混沌工程实践可以帮助验证系统在故障情况下的行为是否符合预期。
数据一致性的未来发展趋势
随着新硬件和新架构的出现,数据一致性技术也在不断发展。区块链技术通过共识机制提供了去中心化环境下的数据一致性解决方案。边缘计算场景下,需要考虑网络延迟更大、连接不稳定的特点。未来,机器学习可能被用于自动调整一致性级别,根据工作负载模式动态优化系统行为。
数据一致性是分布式系统设计的永恒主题,理解其原理和实践对于构建可靠、高效的软件系统至关重要。通过合理选择一致性模型、实现机制和监控策略,可以在满足业务需求的同时获得最佳的系统性能。
常见问题解答
Q1: 强一致性和最终一致性有什么区别?
A1: 强一致性要求所有节点在任何时刻看到的数据都是完全一致的,而最终一致性允许系统在一段时间内处于不一致状态,但最终会达到一致。强一致性通常用于金融交易等关键业务,最终一致性则适用于对实时性要求不高的场景。
Q2: CAP理论中的C、A、P分别代表什么?
A2: C代表一致性(Consistency),A代表可用性(Availability),P代表分区容错性(Partition tolerance)。CAP理论指出,在分布式系统中,这三个特性不可能同时满足,最多只能满足其中两项。
Q3: 为什么说Raft比Paxos更容易实现?
A3: Raft通过引入明确的领导者角色和日志复制机制,将共识过程分解为更易理解的几个部分。相比之下,Paxos的原始描述较为抽象,不同实现之间存在较大差异,增加了理解和实现的难度。
Q4: 在微服务架构中如何保证数据一致性?
A4: 微服务架构通常采用最终一致性模型,通过事件溯源(Event Sourcing
)、Saga模式等技术实现跨服务的数据一致性。这些方法避免了分布式事务的性能开销,但需要应用层处理暂时的不一致状态。