


调用链追踪的基本概念
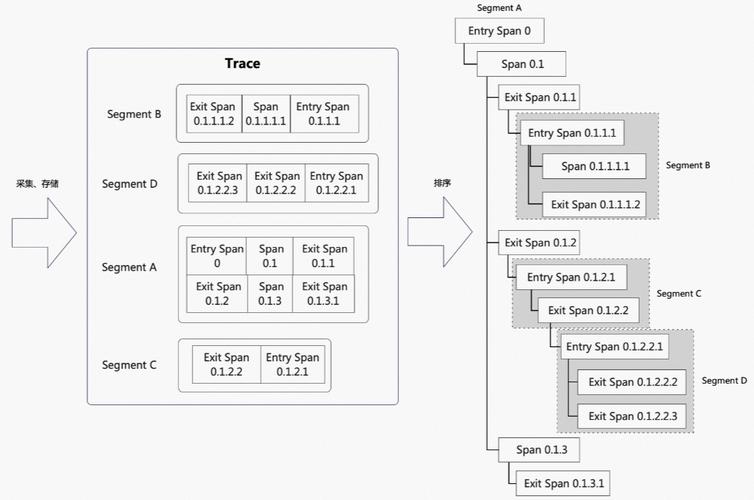
调用链追踪(Distributed Tracing)是一种用于监控和诊断分布式系统的技术手段。它通过记录请求在分布式系统中流转的完整路径,帮助开发者理解系统行为、定位性能瓶颈和排查故障。在微服务架构中,一个用户请求往往需要经过多个服务的处理,调用链追踪能够将这些分散的调用信息串联起来,形成完整的调用图谱。
核心术语解析
Trace(追踪):表示一个完整的请求链路,从客户端发起请求到最终响应返回的全过程。Span(跨度):Trace的基本组成单元,代表一个服务内部或跨服务的一次操作。每个Span包含操作名称、时间戳、持续时间、标签和日志等信息。Annotation(注解):用于记录Span中的关键事件,如客户端发送请求、服务端接收请求等。Context(上下文):用于在服务间传递调用链信息,确保Trace的连续性。
调用链追踪的价值
调用链追踪技术为分布式系统带来了三大核心价值:可视化系统拓扑,直观展示服务间依赖关系;精准定位性能瓶颈,通过分析各Span耗时找出慢请求;快速故障排查,通过Trace日志还原异常发生时的系统状态。这些能力对于保障系统SLA、优化用户体验至关重要。
主流调用链追踪框架比较
目前业界有多种成熟的调用链追踪解决方案,各有特点和适用场景。了解这些框架的异同有助于我们根据实际需求做出合理选择。
Zipkin
Zipkin是Twitter开源的一款分布式追踪系统,基于Google的Dapper论文实现。它采用收集器-存储-查询的三层架构,支持多种后端存储(如Elasticsearch、MySQL等)。Zipkin的优势在于轻量级、易于部署,社区生态丰富,但功能相对基础,缺乏高级分析能力。
Jaeger
Jaeger是Uber开源的端到端分布式追踪系统,后被CNCF接纳为毕业项目。相比Zipkin,Jaeger提供了更强大的查询和分析功能,支持动态采样、依赖分析等高级特性。其架构包含Agent、Collector、Query和UI等组件,部署略复杂但功能全面。
SkyWalking
SkyWalking是国人开发的APM系统,除了调用链追踪外还提供指标监控、服务拓扑、性能剖析等综合能力。它采用探针方式实现无侵入式监控,对Java生态支持尤为完善。SkyWalking的突出优势在于其一体化的监控解决方案和较低的性能开销。
调用链追踪的实现原理
理解调用链追踪的底层实现机制,有助于我们更好地应用和优化这项技术。典型的调用链追踪系统包含数据采集、传输、存储和展示四个关键环节。
上下文传播机制
保持调用链的连续性依赖于上下文信息的跨进程传递。常见的传播方式包括HTTP头注入(如X-B3-TraceId)、消息队列属性扩展和RPC框架拦截。无论采用哪种协议,都需要确保TraceID、SpanID等核心字段能够正确传递。
采样策略
全量采集调用链数据会产生巨大开销,因此需要合理的采样策略。常见方法包括固定比率采样(如1%)、自适应采样(根据系统负载动态调整)和关键路径采样(优先采集特定业务路径)。合理的采样策略能在数据量和代表性间取得平衡。
数据存储模型
调用链数据具有明显的时间序列特征,且查询模式以TraceID检索为主。Elasticsearch是常见的存储选择,其倒排索引结构适合此类查询场景。对于大规模部署,可采用分层存储策略,热数据存Elasticsearch,冷数据归档至对象存储。
调用链追踪的最佳实践
有效应用调用链追踪技术需要遵循一些实践准则,避免常见陷阱,最大化技术价值。
合理的Span划分
Span粒度过粗会丢失关键细节,过细则增加系统负担。建议按照业务逻辑单元划分Span,如API端点、数据库操作、外部服务调用等。对于耗时操作,可进一步拆分为多个子Span以精确定位瓶颈。
有意义的标签设计
标签(Tag)是Span的重要元数据,应包含业务和技术的双重信息。典型标签包括:业务属性(如订单ID、用户类型)、技术指标(如HTTP状态码、SQL语句)和性能数据(如响应大小、缓存命中)。良好的标签设计能极大提升后续分析效率。
与其他监控系统集成
调用链追踪应与指标监控、日志系统协同工作,形成完整的可观测性体系。通过关联TraceID,可以在指标异常时快速定位相关调用链,或在分析调用链时查看对应服务指标,实现多维度的故障诊断。
常见问题解答
Q1: 调用链追踪对系统性能有多大影响?
A1: 合理配置的调用链追踪系统通常带来1%-5%的性能开销。通过异步上报、采样策略和轻量级SDK等手段可以最小化影响。实际部署前建议进行性能压测评估。
Q2: 如何处理跨语言服务的调用链追踪?
A2: 选择支持多语言的追踪系统(如Jaeger、SkyWalking),确保各语言SDK遵循相同的上下文传播协议。对于不支持的语言,可通过手动注入HTTP头或扩展消息属性实现基本追踪。
Q3: 调用链数据应该保留多长时间?
A3: 取决于业务需求和存储成本。通常生产环境保留7-30天,同时可配置长期归档重要业务的调用链数据。建议设置分层保留策略,结合自动清理机制。
Q4: 如何利用调用链追踪优化系统性能?
A4: 通过分析调用链可以:识别串行调用改为并行的机会、发现重复计算或查询、定位慢SQL或外部API、优化服务依赖关系。定期分析关键路径的调用链能持续提升系统性能。
调用链追踪技术已成为现代分布式系统不可或缺的组成部分。通过系统性地实施调用链追踪,团队可以获得前所未有的系统可见性,显著提升运维效率和故障恢复能力。随着云原生技术的普及,调用链追踪将与服务网格、Serverless等新技术深度融合,持续演进其能力和应用场景。