


纠删码的基本原理
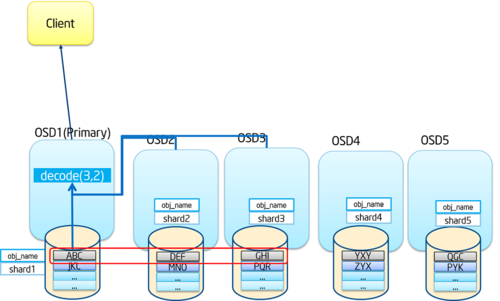
纠删码是一种前向纠错编码技术,其核心思想是将原始数据分割成k个数据块,通过数学算法生成m个校验块。这些数据块和校验块共同构成一个编码组(n=k+m),即使其中部分块丢失或损坏,系统仍能通过剩余的有效块重建出完整数据。这种机制使得纠删码能够在保证数据可靠性的同时,将存储开销控制在合理范围内。
纠删码的数学基础
纠删码的实现依赖于多种数学理论,主要包括:
- 里德-所罗门码(Reed-Solomon Code):最常用的纠删码实现方式,基于有限域运算
- 低密度奇偶校验码(LDPC):具有高效解码特性的现代编码
- 喷泉码(Fountain Code):特别适合网络传输的随机编码方式
纠删码与传统副本技术的对比
在分布式存储系统中,数据冗余是保证可靠性的基本手段。传统方法通常采用多副本复制(如3副本),而纠删码则提供了更高效的替代方案。
存储效率对比
以存储1TB数据为例:
- 3副本方案需要3TB存储空间,冗余度为200%
- 采用10+4纠删码配置(10个数据块+4个校验块)仅需1.4TB存储空间,冗余度仅为40%
可靠性对比
虽然纠删码的存储效率更高,但其可靠性取决于具体配置。一个设计合理的纠删码方案(如6+3)可以容忍任意3个块失效,与3副本的容错能力相当,但存储开销大幅降低。
纠删码的主要应用场景
纠删码技术已广泛应用于各类大规模存储系统中,主要包括:
分布式存储系统
如HDFS、Ceph等开源分布式文件系统都支持纠删码功能。Facebook的f4存储系统采用纠删码技术,节省了约75%的存储空间。
云存储服务
AWS、Azure、阿里云等主流云服务商在其对象存储服务中应用纠删码技术,既保证了数据可靠性,又降低了运营成本。
冷数据存储
对于访问频率较低的冷数据,纠删码是理想的存储方案,可以在保证数据可恢复性的前提下,显著降低长期存储成本。
纠删码技术正在重塑现代存储架构,通过巧妙的数学算法在存储效率和数据可靠性之间找到了最佳平衡点。随着分布式系统规模的不断扩大和数据量的持续增长,纠删码的应用前景将更加广阔。未来,结合机器学习等新技术,纠删码有望实现更智能的自适应配置,进一步提升大规模存储系统的性能和效率。
关于纠删码的常见问题
1. 纠删码会影响数据读取性能吗?
是的,当部分数据块不可用时,纠删码需要进行解码重建,这会增加读取延迟。但在数据完整的情况下,读取性能与普通存储相当。
2. 如何选择合适的纠删码配置?
这取决于数据的重要性和访问模式。对于关键热数据,可采用较低冗余比(如8+3);对于冷数据,则可使用更高冗余比(如10+4)以节省空间。
3. 纠删码可以完全替代副本技术吗?
不能完全替代。在实际系统中,通常采用混合策略:对热数据使用副本,对冷数据使用纠删码,以达到性能与成本的平衡。