


匿名化技术的基本概念
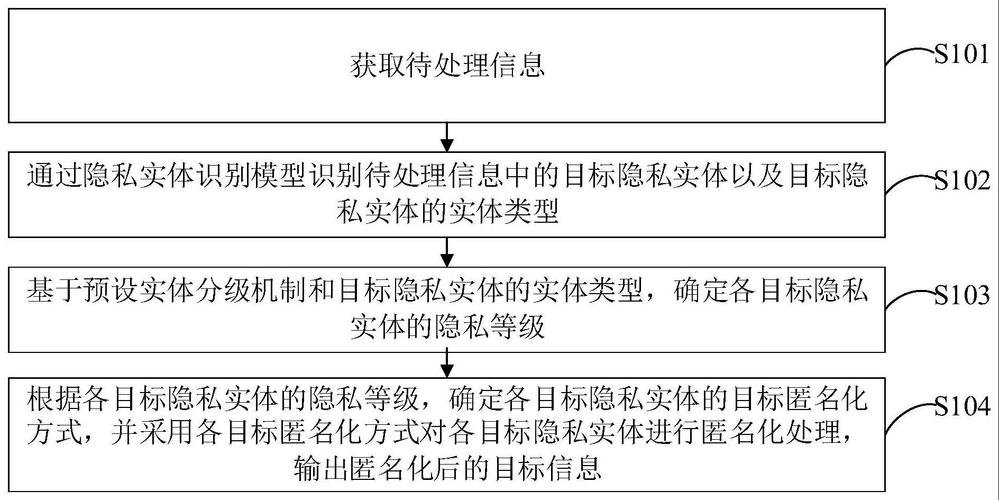
匿名化技术是指通过特定方法处理数据,使其无法直接或间接识别特定个人身份的技术手段。与简单的去标识化不同,真正的匿名化要求处理后数据在任何情况下都无法重新识别个人身份。根据欧盟《通用数据保护条例》(GDPR)的定义,匿名化数据不再属于个人数据范畴,因此不受隐私法规的严格限制。
匿名化与假名化的区别
假名化只是用假名替代真实标识符,但保留了重新识别的可能性;而匿名化则彻底切断了数据与个人身份的联系。,医疗研究中用患者编号代替姓名是假名化,而将年龄从具体数字改为"30-40岁"范围则属于匿名化技术的一部分。
主流匿名化技术方法
数据泛化技术
数据泛化是通过降低数据精度来实现匿名化的常用方法。具体包括:将具体年龄改为年龄段(如20-30岁);将详细地址改为城市或区域;将精确工资改为收入区间等。泛化程度越高,隐私保护效果越好,但数据实用性也会相应降低。
K-匿名模型
K-匿名要求数据集中每一条记录至少与其他K-1条记录在准标识符属性上不可区分。,在一个包含性别、年龄、邮编的患者数据集中,确保每个性别-年龄-邮编组合至少有K个相同记录。这种方法能有效防止链接攻击,但实现时需要仔细选择K值和准标识符。
差分隐私技术
差分隐私是一种数学上严格定义的隐私保护框架,通过在数据或查询结果中添加精心校准的噪声,确保单个记录的存在与否不会显著影响输出结果。苹果和谷歌等科技公司已广泛采用差分隐私技术收集用户统计信息而不泄露个人数据。
匿名化技术的应用场景
匿名化技术在多个领域发挥着重要作用:医疗健康领域用于共享患者数据进行研究;金融行业用于反欺诈分析和风险建模;政府统计部门用于发布人口普查数据;互联网公司用于分析用户行为模式而不侵犯隐私。
一个典型应用案例是COVID-19疫情期间,各国卫生部门通过匿名化技术共享患者流行病学数据,既支持了科学研究,又保护了患者隐私。移动应用也广泛使用匿名化技术收集位置数据,用于交通流量分析而不追踪个人行踪。
匿名化技术面临的挑战
尽管匿名化技术已取得显著进展,但仍面临诸多挑战:数据效用与隐私保护的平衡问题;应对不断演进的去匿名化攻击技术;处理高维数据的匿名化困难;以及跨组织数据共享时的标准统一问题等。随着机器学习技术的发展,新型隐私推断攻击使得传统匿名化方法可能不再足够安全。
未来匿名化技术发展将更加注重组合多种方法(如K-匿名与差分隐私结合),开发自适应匿名化算法,以及利用同态加密等密码学技术增强保护效果。区块链与匿名化技术的结合也是一个值得关注的方向,有望实现可验证的隐私保护数据共享。
匿名化技术作为平衡数据利用与隐私保护的关键工具,其重要性将持续增长。组织在实施匿名化时,应当根据数据类型、使用场景和法规要求,选择适当的技术组合,并定期评估其有效性。同时,匿名化不应被视为隐私保护的唯一措施,而应作为多层防御策略的一部分,与访问控制、加密等其他安全措施配合使用。
常见问题解答
问题1:匿名化数据真的无法被重新识别吗?
答:没有任何匿名化方法能提供100%的不可重新识别保证,但良好的匿名化技术可以使得重新识别在计算上不可行或需要不合理的资源投入。关键在于评估数据的具体使用场景和可能面临的攻击风险。
问题2:如何选择适合自己数据的匿名化方法?
答:选择匿名化方法应考虑数据类型(结构化/非结构化
)、数据使用目的、隐私保护要求等因素。结构化数据适合K-匿名或差分隐私,而复杂数据分析场景可能更适合差分隐私。建议咨询数据隐私专家进行评估。
问题3:匿名化技术会影响数据分析结果吗?
答:所有匿名化技术都会在一定程度上影响数据质量,但影响程度取决于技术选择和参数设置。,差分隐私添加的噪声会影响统计结果的精确度,但通常保持在可接受范围内。需要在隐私保护与数据效用间找到适当平衡。