


联邦学习的核心概念
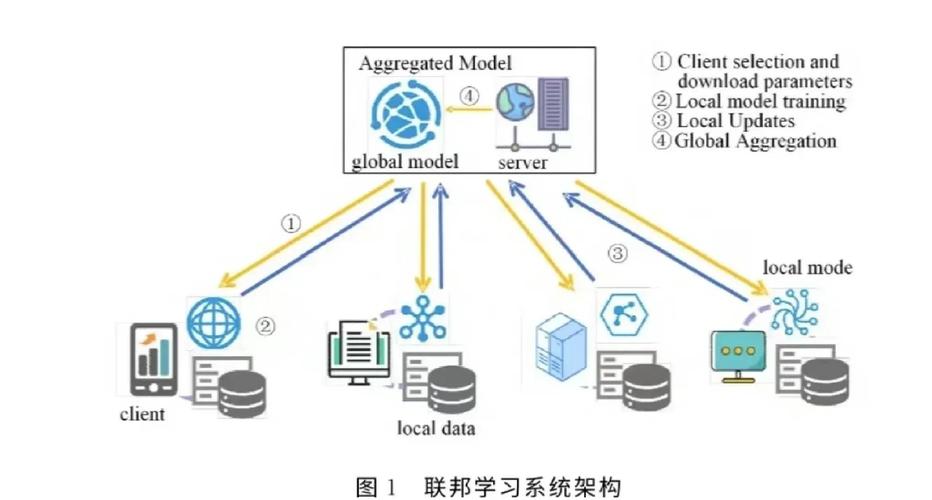
联邦学习作为一种分布式机器学习范式,其核心在于"数据不动,模型动"的理念。与传统集中式机器学习不同,联邦学习中的训练数据始终保留在本地设备或边缘服务器上,只有模型参数或梯度信息会在参与方之间进行交换。这种设计既保护了数据隐私,又实现了多方数据的协同利用。
联邦学习的三大特征
1. 数据本地化:参与方的原始数据不出本地,仅共享模型更新信息
2. 协同训练:多个参与方共同贡献模型训练过程
3. 隐私保护:通过加密技术、差分隐私等方法增强数据安全性
联邦学习的工作原理
基本训练流程
联邦学习的典型工作流程包括以下几个步骤:中央服务器初始化全局模型并分发给各参与方;各参与方在本地数据上训练模型,计算模型参数更新;接着,参与方将更新上传至中央服务器;服务器聚合所有更新,生成新的全局模型。这个过程会迭代进行,直到模型收敛。
常见的聚合算法
1. FedAvg(联邦平均):最简单的聚合方法,对参数更新进行加权平均
2. FedProx:引入近端项解决数据异构性问题
3. FedMA:层匹配聚合方法,适用于深度神经网络
联邦学习的应用场景
联邦学习技术在多个领域展现出巨大潜力。在医疗健康领域,医院间可以通过联邦学习共享医疗知识而无需共享患者敏感数据;在金融领域,银行可以联合训练反欺诈模型而不泄露客户交易信息;在智能终端领域,手机厂商可以基于用户使用习惯改进输入法预测,同时保护用户隐私。
典型应用案例
1. 医疗影像分析:多家医院联合训练AI辅助诊断系统
2. 智能推荐:电商平台基于用户行为数据优化推荐算法
3. 物联网设备:智能家居设备协同学习用户习惯
联邦学习的挑战与未来
尽管联邦学习具有诸多优势,但也面临一些挑战。数据异构性可能导致模型偏差;通信开销可能影响训练效率;安全性问题如模型逆向攻击需要防范。未来,联邦学习将与边缘计算、区块链等技术深度融合,发展出更高效、更安全的变体,如垂直联邦学习、联邦迁移学习等。
未来发展方向
1. 通信效率优化:减少参与方与服务器间的数据传输量
2. 个性化联邦学习:为不同参与方定制个性化模型
3. 跨模态联邦学习:处理不同类型数据的联合训练
联邦学习作为分布式机器学习技术的重要分支,正在重塑数据隐私保护与AI发展的平衡关系。随着技术的不断成熟,联邦学习将在更多领域发挥关键作用,推动人工智能向着更安全、更可信的方向发展。
常见问题解答
1. 联邦学习与传统分布式学习有什么区别?
联邦学习与传统分布式学习的主要区别在于数据存储方式。传统分布式学习通常需要将数据集中存储或在不同节点间共享,而联邦学习中数据始终保留在本地,只有模型参数或梯度信息会被共享。
2. 联邦学习如何保证数据隐私?
联邦学习通过多种技术保障数据隐私,包括:1)原始数据不出本地;2)使用加密技术(如同态加密)保护传输的模型参数;3)应用差分隐私技术防止从模型更新中推断出原始数据。
3. 哪些场景不适合使用联邦学习?
联邦学习不适合以下场景:1)参与方数据量差异过大,可能导致模型偏差;2)需要实时或低延迟响应的应用,因为联邦学习的通信开销较大;3)数据特征维度完全不同的跨机构场景,可能需要特殊处理。
4. 如何评估联邦学习模型的性能?
评估联邦学习模型性能可以从以下几个方面考虑:1)全局模型在测试集上的准确率;2)模型在不同参与方本地数据上的表现差异;3)通信轮次与模型性能的平衡;4)隐私保护强度与模型性能的权衡。