


模型版本控制基础概念
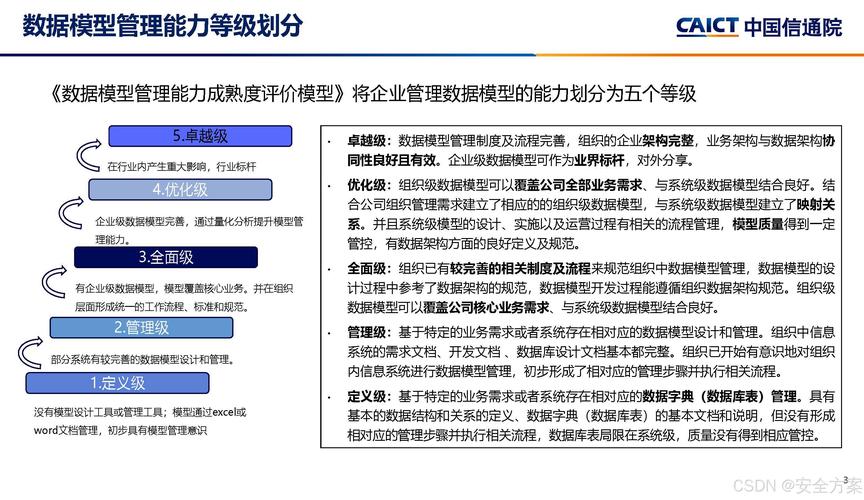
模型版本控制是指对机器学习模型进行系统化管理的过程,包括跟踪模型变更、记录训练参数、存储模型权重以及管理相关依赖项。与传统的软件版本控制类似,模型版本控制也需要考虑版本标识、变更历史、分支合并等核心问题。模型版本控制有其独特性,因为模型不仅包含代码,还包括训练数据、超参数、权重等复杂组件。
为什么模型需要专门的版本控制?
不同于常规软件,机器学习模型具有数据依赖性、非确定性训练过程和复杂的依赖关系。一个模型的性能不仅取决于代码本身,还受到训练数据质量、数据预处理流程、超参数设置等多重因素影响。因此,传统的Git等版本控制系统无法完全满足模型管理的需求,需要专门的解决方案来跟踪这些复杂关系。
模型版本控制的关键组件
完整的模型版本控制系统通常包含以下核心组件:模型注册表(用于存储和管理模型版本
)、元数据存储(记录训练参数和环境信息
)、工件存储(保存模型权重和二进制文件
)、实验跟踪(记录训练过程和指标)以及部署管道(将模型推送到生产环境)。这些组件共同构成了模型生命周期管理的基础设施。
模型版本控制最佳实践
实施有效的模型版本控制需要遵循一系列最佳实践。建立清晰的版本命名规范至关重要。常见的版本控制方案包括语义化版本控制(SemVer
)、基于日期的版本控制以及混合方法。无论选择哪种方案,关键是要保持一致性,并在整个团队中严格执行。
版本命名规范示例
语义化版本控制(MAJOR.MINOR.PATCH)特别适合模型版本管理:MAJOR版本表示不兼容的API变更,MINOR版本表示向后兼容的功能性增强,PATCH版本表示向后兼容的问题修正。,从1.2.3升级到2.0.0表示模型架构发生了重大变化,可能需要更新客户端代码。
模型元数据管理
完善的元数据记录是模型可重现性的关键。每次模型训练都应记录完整的配置信息,包括但不限于:训练数据集版本、特征工程步骤、超参数设置、训练环境(框架版本、硬件配置
)、评估指标以及任何相关注释。这些元数据不仅有助于问题排查,还能支持模型审计和合规要求。
模型部署与版本控制集成
将模型版本控制与部署流程紧密集成可以显著提高运维效率。现代MLOps平台通常提供自动化部署管道,能够将特定版本的模型安全可靠地推送到生产环境。这种集成支持多种部署策略,包括蓝绿部署、金丝雀发布和影子模式等,确保新模型版本的平滑过渡。
部署策略选择
蓝绿部署通过维护两个完全独立的生产环境来最小化风险,适用于关键业务场景。金丝雀发布则逐步将流量从旧版本转移到新版本,允许在小规模验证模型性能。影子模式让新版本模型并行处理请求但不影响实际输出,特别适合评估模型行为而无需承担风险。选择哪种策略取决于业务需求、风险承受能力和基础设施能力。
模型监控与回滚机制
完善的模型版本控制系统必须包含监控和回滚能力。一旦部署新版本,需要持续监控其性能指标(如预测延迟、准确率、业务KPI等)。如果检测到异常,应能快速回滚到之前的稳定版本。这种能力依赖于健全的版本控制和自动化运维流程的结合。
常见问题解答
Q1: 模型版本控制与代码版本控制有何不同?
A1: 模型版本控制不仅管理代码,还需要跟踪训练数据、超参数、权重等组件,以及它们之间的复杂关系。模型版本通常更大(GB级别),需要专门的存储解决方案,而代码版本控制主要处理文本文件。
Q2: 如何选择适合的模型版本控制工具?
A2: 选择工具时应考虑团队规模、技术栈、云环境等因素。对于小型团队,MLflow或DVC可能足够;企业级解决方案则可能需要Vertex AI、Sagemaker或Azure ML等平台服务。关键评估标准包括:是否支持您的ML框架、与现有CI/CD管道的集成能力、元数据管理功能以及团队学习曲线。
Q3: 如何处理模型版本控制中的大数据集?
A3: 对于大型数据集,建议使用数据版本控制工具(如DVC)或专门的存储解决方案。可以考虑只版本化数据集的元数据或指纹(如校验和),而不是存储完整副本。另一种方法是使用增量存储技术,只记录数据变更部分。
模型版本控制是机器学习工程中的关键环节,直接影响模型的可重现性、可维护性和部署可靠性。通过实施系统的版本控制策略,团队能够更有效地协作、更快地迭代模型,并确保生产环境的稳定性。随着MLOps实践的不断成熟,模型版本控制将继续演进,为AI项目提供更强大的支持。