


数据投毒的基本概念与原理
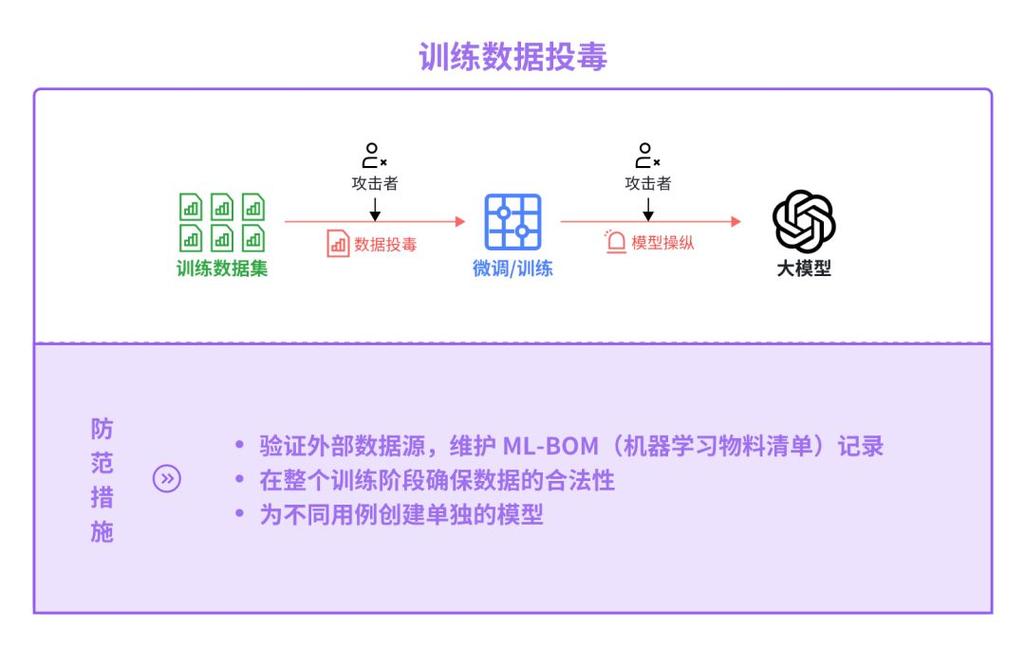
数据投毒(Data Poisoning)是指攻击者通过向机器学习系统的训练数据中注入恶意样本,从而影响模型训练过程和最终决策的一种对抗性攻击手段。与传统的网络攻击不同,数据投毒攻击更加隐蔽和持久,因为有毒数据一旦被模型学习,其影响将持续存在于系统中。
数据投毒的工作原理
数据投毒攻击通常发生在模型训练阶段,攻击者通过以下方式实施:1)直接向训练数据集中插入错误标记的样本;2)修改现有数据的标签;3)精心设计看似正常但实际具有误导性的数据。这些有毒数据会改变模型的决策边界,使其在特定情况下产生攻击者期望的错误输出。
数据投毒的攻击目标
数据投毒的主要目标包括:监督学习中的分类模型、推荐系统、异常检测系统等。攻击者可能出于经济利益、竞争目的或纯粹破坏意图实施此类攻击。,通过投毒电商推荐系统,攻击者可以提升特定商品的曝光率;针对垃圾邮件过滤器投毒,可使恶意邮件绕过检测。
常见的数据投毒攻击类型
根据攻击目标和实施方式的不同,数据投毒攻击可分为多种类型,每种类型都有其独特的特点和危害程度。
标签翻转攻击(Label Flipping)
这是最简单的数据投毒形式,攻击者仅改变训练数据中样本的标签,而不修改特征。,将垃圾邮件的标签从"垃圾"改为"正常",使分类器学习错误的关联模式。研究表明,仅需污染5%的训练数据,就可使某些分类器的准确率下降20%以上。
特征污染攻击(Feature Contamination)
攻击者精心设计具有特定特征组合的样本并注入训练集。这类攻击更加隐蔽,因为数据看起来完全合理,但特征组合可能导致模型学到错误的决策规则。,在医疗诊断系统中,某些症状组合可能被设计为总是导致误诊。
后门攻击(Backdoor Attack)
这是一种更高级的数据投毒形式,攻击者在训练数据中植入特定的"触发器"(如特定像素模式),当模型部署后,输入中包含该触发器时,模型会产生预设的错误输出。后门攻击特别危险,因为模型在正常输入下表现良好,只在特定情况下失效,极难被发现。
数据投毒的检测与防御策略
面对日益复杂的数据投毒威胁,研究人员已开发出多种检测和防御技术。有效的防御需要从数据、算法和系统多个层面构建防护体系。
数据层面的防御措施
1. 数据来源验证:严格审核训练数据的来源和采集过程,确保数据供应链安全;2. 异常检测:使用统计方法和可视化工具识别数据中的异常模式和离群点;3. 数据清洗:在训练前对数据进行去噪和过滤,移除可疑样本;4. 数据多样性:确保训练数据覆盖各种场景,减少攻击面。
算法层面的防御技术
1. 鲁棒学习算法:采用对噪声和异常值不敏感的算法,如支持向量机、决策树等;2. 差分隐私:在训练过程中添加受控噪声,限制单个样本对模型的影响;3. 对抗训练:在训练过程中主动生成并包含对抗样本,提高模型鲁棒性;4. 模型验证:使用独立的验证集定期测试模型性能,检测潜在的数据污染。
系统层面的防护机制
1. 持续监控:建立模型性能监控系统,及时发现异常行为;2. 模型解释性:采用可解释AI技术,理解模型决策依据,识别可疑模式;3. 多模型集成:使用多个独立训练的模型进行集成决策,降低单个被污染模型的影响;4. 安全更新:定期使用干净数据重新训练模型,消除可能的累积污染。
数据投毒的实际案例与影响
近年来,数据投毒攻击已在多个领域造成实际影响,这些案例为我们提供了宝贵的经验教训。
数据投毒作为一种新型网络安全威胁,其危害性不容小觑。随着AI系统在各行业的深入应用,数据投毒攻击面将持续扩大。防御数据投毒需要技术、管理和法规的多管齐下。企业和组织应提高安全意识,建立完善的数据治理体系,采用先进的检测和防御技术,同时积极参与行业信息共享,共同应对这一挑战。只有保持警惕并采取积极措施,我们才能在享受AI技术红利的同时,有效规避数据投毒带来的风险。
常见问题解答
问题1:数据投毒和对抗样本攻击有什么区别?
数据投毒发生在模型训练阶段,通过污染训练数据影响模型;而对抗样本攻击发生在模型部署后,通过精心修改输入数据欺骗已训练好的模型。数据投毒的影响更持久,对抗样本攻击通常只影响单个预测。
问题2:如何判断我的模型是否遭受了数据投毒攻击?
可能的迹象包括:1)模型在特定类别或场景下性能突然下降;2)模型开始产生不符合常理的预测;3)验证集表现良好但实际应用中出现异常。可通过审计训练数据、分析模型决策模式和监控预测分布来进行检测。
问题3:中小企业如何低成本防御数据投毒?
中小企业可以采取以下经济有效的措施:1)使用经过验证的公开数据集而非自行采集;2)采用开源的鲁棒学习算法;3)定期交叉验证模型性能;4)限制单个数据源的影响权重;5)参与行业安全信息共享,了解最新威胁情报。