


高可用性系统的核心设计原则
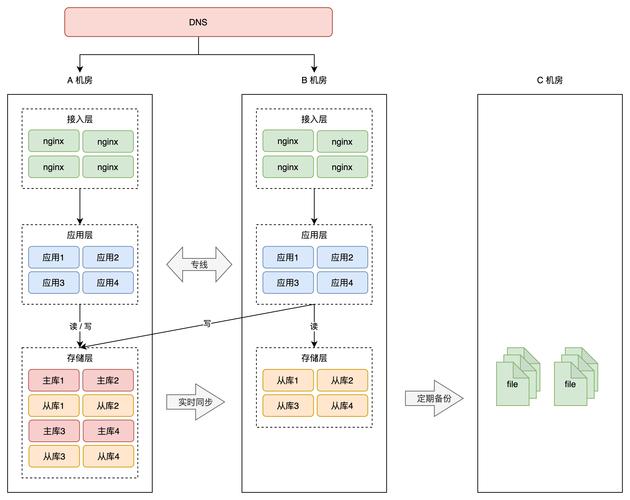
在数字化基础设施构建中,高可用性(High Availability)已成为衡量系统健壮性的黄金标准。该设计理念要求系统在硬件故障、网络中断或流量激增等异常场景下,仍能持续提供不低于99.9%的服务可用性(SLA)。要实现这个目标,工程师必须遵循去中心化架构原则,通过分布式节点部署消除单点故障风险。
如何平衡资源利用率与系统冗余度?这需要引入故障域(Failure Domain)隔离机制,将计算、存储、网络资源划分为独立单元。当某个物理机柜或数据中心发生故障时,负载均衡器能自动将流量切换至健康节点。某电商平台的实践数据显示,采用三地五中心部署模式后,其年度服务中断时间从8.76小时降至26.3秒。
关键技术组件与实现路径
实现高可用性的核心技术栈包含三大支柱:容器编排系统、服务网格和混沌工程平台。Kubernetes通过Pod自动重启机制和滚动更新策略,确保应用实例持续可用。Istio服务网格则运用熔断器(Circuit Breaker)和超时控制,防止局部故障扩散引发雪崩效应。
在数据持久层,多主数据库同步技术突破传统主从架构的限制。CockroachDB采用Raft共识算法,实现跨地域数据强一致性。某金融机构采用该方案后,交易系统在区域性网络中断时仍能保持数据完整性,故障切换时间从分钟级缩短至毫秒级。
典型行业应用与效果验证
案例:AWS云计算平台容灾体系
亚马逊云科技(AWS)的可用区(Availability Zone)设计是业界标杆,每个区域包含3个以上独立数据中心。其全局流量管理器Route 53能实时监测节点健康状态,配合自动扩展组(Auto Scaling Group)实现秒级资源调度。2023年AWS技术白皮书披露,采用多活架构的客户系统平均恢复时间目标(RTO)降低至45秒,数据恢复点目标(RPO)趋近于零。
该体系特别值得借鉴的是故障演练机制,通过GameDay模拟真实灾难场景。在最近的区域级中断测试中,系统自动触发故障转移流程,2000余个微服务在78秒内完成跨区迁移。这种主动容错验证方式,显著提升了系统对未知风险的应对能力。
构建高可用性系统是项系统工程,需要从架构设计、技术选型到运维策略的全链路优化。通过分布式部署消除单点依赖,利用智能监控实现故障预测,结合自动化工具缩短应急响应时间。随着云原生技术和AIops的成熟,系统可用性正从"被动容灾"向"主动免疫"演进,为企业数字化转型提供坚实的技术底座。