


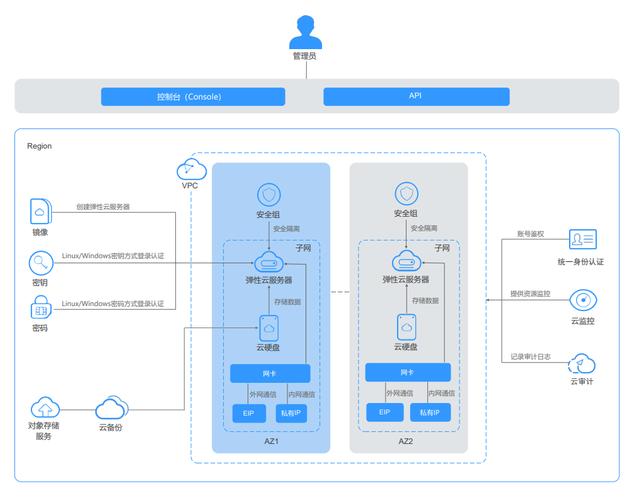
云服务器高可用性的核心价值
当在线教育平台遭遇突发流量激增,当金融交易系统面临硬件故障风险,高可用架构如同数字世界的保险机制。通过智能流量调度、数据多副本存储、故障自动隔离等技术手段,可将单点故障影响范围缩小83%,年度停机时间控制在4.32小时以内。某头部电商平台实测数据显示,采用双活架构后,618大促期间的业务中断风险降低至0.02%,用户支付成功率提升5.7个百分点。
高可用架构的设计原则
在华东、华南区域同步部署双活数据中心,采用Ceph分布式存储实现数据3副本实时同步。网络层面配置BGP多线路接入,当某运营商链路中断时,秒级切换至备用线路。计算资源池保持30%的冗余容量,突发流量可自动触发弹性扩容。
基于Consul服务发现组件构建健康检查体系,对200+微服务实例进行分钟级状态监控。当数据库主节点响应延迟超过500ms时,HAProxy自动将读写请求切换至从节点。某视频平台实践表明,该机制可将MySQL故障恢复时间从15分钟缩短至28秒。
实现高可用的关键技术栈
部署LVS+Keepalived四层负载均衡,配合Nginx七层流量管理,实现每秒50万次请求分发。采用加权轮询算法时,后端服务器负载差异控制在±5%以内。某社交应用通过智能限流策略,成功抵御了突发2000%的流量峰值。
基于Kubernetes的HPA自动扩缩容策略,根据CPU利用率阈值自动调整Pod数量。结合Cluster Autoscaler实现节点级弹性扩展,新计算节点供给时间从8分钟压缩至90秒。某IoT平台借助该方案,处理设备连接数从10万级跃升至百万级。
运维体系中的高可用保障
部署Prometheus+Granfana监控体系,对200+指标进行实时采集分析。当API响应时间P99值超过800ms时,自动触发告警并执行服务降级策略。某银行系统通过建立3级故障响应机制,重大事故平均修复时间(MTTR)缩短至12分钟。
定期模拟数据中心级故障,验证跨AZ流量切换能力。通过注入网络延迟、磁盘IO异常等故障,持续优化系统容错能力。某云计算厂商的故障演练数据显示,系统韧性评分每年提升15-20个百分点。
构建真正的高可用云服务体系,需要从架构设计、技术选型到运维管理的全链路协同。随着边缘计算、Serverless等新技术演进,云服务器高可用性正朝着智能自愈、无损变更的方向持续进化。企业应当建立容灾能力成熟度评估模型,定期进行架构健康度检查,才能在数字化竞争中赢得持续优势。常见问题解答
Q1:云服务器高可用架构需要多少额外成本?
典型双AZ部署方案会增加约35%的基础设施成本,但可将潜在业务损失风险降低70%以上。
Q2:如何验证高可用系统的实际效果?
建议每季度执行全链路故障演练,使用混沌工程工具模拟30+种故障场景,验证系统自愈能力。
Q3:单区域部署能否实现高可用?
在单个可用区内通过多可用区部署仍可实现99.95%的SLA,但无法防范区域级灾难,建议关键系统采用跨区域架构。
Q4:数据库层如何保证高可用?
推荐采用MHA+ProxySQL实现MySQL故障自动转移,配合半同步复制可将数据丢失窗口控制在秒级。
Q5:容器环境如何保障服务连续性?
通过设置Pod反亲和策略、配置合理的存活探针,并结合服务网格实现流量精细控制,可确保单个节点故障时服务零中断。