


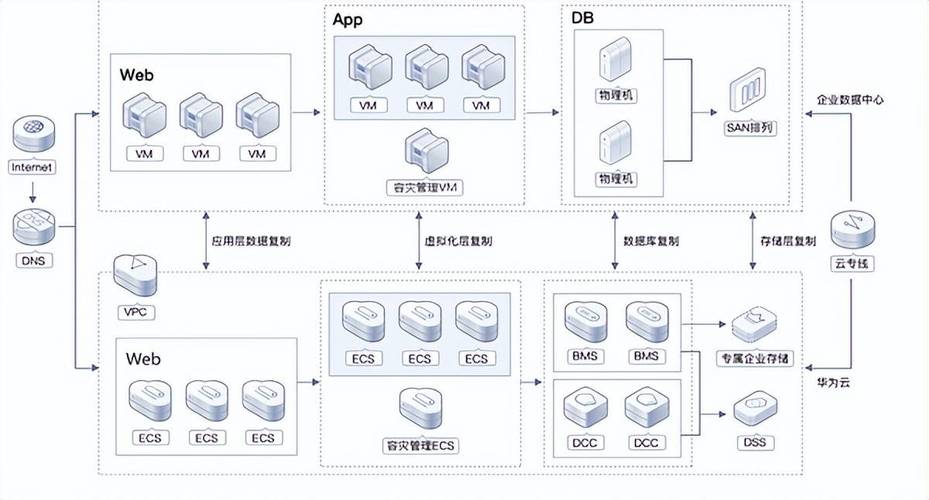
云服务器灾难恢复的本质特征
云服务器灾难恢复不同于传统备份方案,它构建在云计算弹性架构之上,通过智能化的故障转移机制实现业务连续性。以AWS的Disaster Recovery解决方案为例,其采用实时数据同步技术,在跨可用区部署热备环境,当主服务器集群出现故障时,系统能在90秒内自动切换至备用节点。这种基于云原生的灾难恢复体系,相比自建灾备中心可降低67%的运维成本,同时将恢复时间目标(RTO)压缩至传统方案的1/5。
灾难恢复计划的核心要素
完整的云灾难恢复方案必须包含三个关键维度:数据保护层设计、服务恢复优先级划分、演练验证机制。微软Azure的灾备方案采用3-2-1-1数据保护原则,即保留3份数据副本,存储在2种不同介质,其中1份离线保存,并确保1份可快速恢复的云备份。业务系统需要按照RPO(恢复点目标)和RTO分级管理,核心交易系统通常要求RPO≤5分钟,RTO≤15分钟,而辅助系统可放宽至RPO 4小时/RTO 8小时。
多云架构下的容灾部署
领先企业正在采用跨云服务商的灾备策略,将阿里云作为主生产环境,同时在华为云部署灾备集群。这种架构需要解决数据同步延迟和API兼容性问题,Gartner推荐的解决方案是采用Velero等开源工具实现Kubernetes集群的跨云迁移,配合Ceph的对象存储跨区域复制功能,可将PB级数据的同步延迟控制在毫秒级。某金融客户的实践显示,多云灾备架构使年度服务可用性从99.95%提升至99.995%,相当于每年故障时间从4.38小时降至0.88小时。
自动化恢复的技术实现
智能化灾难恢复依赖三大核心技术:基础设施即代码(IaC)、混沌工程平台、AI故障预测。Terraform编写的声明式配置文件可确保灾备环境与生产环境完全一致,避免配置漂移问题。Netflix开发的Chaos Monkey混沌工程工具,能模拟各种故障场景验证恢复流程。更前沿的是Google Cloud的AI运维系统,通过分析千万级日志事件,可提前72小时预测存储故障,准确率达89%。
成本优化的关键策略
云灾备成本控制需要精细化的资源调度策略,AWS的S3 Intelligent-Tiering存储方案可根据访问频率自动调整数据存储层级,使冷数据存储成本降低40%。对于非关键系统,可采用"开关式灾备"模式,日常仅保留最低配置的待机实例,灾难发生时通过Auto Scaling快速扩容。某电商平台采用此方案后,灾备成本从每月12万美元降至3.5万美元,同时满足SLA要求。
云服务器灾难恢复已从可选方案演变为数字化企业的生存必需品。通过构建智能化、自动化、多云化的灾备体系,企业能将业务中断风险降低90%,数据丢失概率控制在0.001%以下。随着边缘计算和5G技术的发展,未来的灾备方案将向"分布式生存"演进,实现任何节点故障都不影响全局服务连续性。常见问题解答
- 云灾备需要准备多少预算?
初期投入建议控制在IT总预算的15-20%,重点保障核心系统的RTO/RPO要求。 - 如何选择灾备云服务商?
需评估服务商的可用区数量、API兼容性、数据传输定价三个核心指标。 - 数据加密是否影响恢复速度?
采用AES-NI硬件加速的加密方案,性能损耗可控制在3%以内。 - 灾备演练频率如何设定?
关键系统每季度实战演练,其他系统每年至少两次模拟演练。 - 混合云如何实现灾备?
推荐使用Azure Stack HCI构建本地恢复点,与公有云形成双向同步。